I have been running baserow for a while now without any issues. Due to the limited resources on my current server I am planning to move my baserow instance over to a more powerful machine.
On my new machine I am facing a strange problem. Although Baserow seems to run perfectly I am getting disconnected after working with Baserow for 5-20 minutes.
I am running the docker image baserow:1.13.3 behind a Caddy Reverse Proxy. Port 80 from the container is mapped to 3001 on the host.
Caddyfile entry:
myurl.com {
reverse_proxy localhost:3001
}
I am running the same docker image without problems on my old host. There are diffenres between the systems, but I cannot see how these could cause the issue:
Old server:
Arch Linux
Docker
Traefik
New Server:
NixOS
Podman
Caddy
Does anyone have an idea what could cause this issue?
Thanks for helping out. I have sent you the logfile from the container.
I do not remember the URL exactly, but it was some sort of redirect url (sorry I am at work and unable to reproduce this right now)
This happens when I am actively working and when baserow is just open doing nothing. Basically you click something and get to this redirect url. If the backend is available you are redirected to the login, otherwise you get a 404.
I had to switch NixOS generations back, that’s why the container version was reverted to 1.13.
Have baserow running on 1.14.0 now, the problems seems to be gone
Suddenly after doing something for about 20 minutes or just randomly you get redirected to a 404 page
You then have to log back in
Could you provide/email me:
The latest logs from your docker container once again
The command with anonymized environment variables or .env file you are using to launch and run your Baserow server
If you know how, in browsers you can right click on the page and click “inspect” to open a debug window. In this window it would be very useful for me to see the contents of the “network” tab and “console” tab immediately after you hit this issue. But I believe these tabs need to be opened and visible prior to the error occuring for it to show up in them.
I have a suspicion this is happening when your login token expires, but the token refreshing process fails and you get logged out somehow.
For your clarification question:
I have run my baserow installation on another server for month without problems. This problem seems to be happening only on the new server where my instance will be migrated to as soon as I fixed this problem.
There 3 key differences between the servers:
OS: new system runs NixOS / old system runs Arch linux
Reverse proxy: new system runs Caddy / old system runs Traefik
Docker: news system runs container with podman as systemd service / old systems runs regular docker
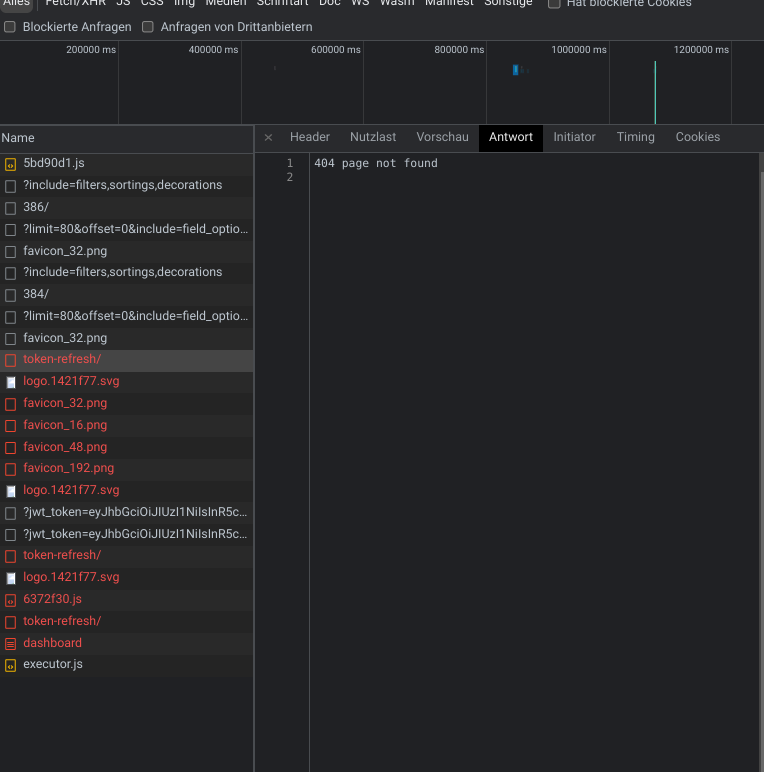
Hm yeh it definitely shouldn’t be responding with 404. Could you select the red 404 token-refresh row in the network log and provide the contents of the “response” tab that appears on the right?
Edit: And also in the Headers tab the “Response Headers” section?
I’m trying to figure out if its a reverse proxy between Baserow and your browser that is returning 404, or Baserow’s API server itself.
Hi @m3tam3re so that 404 response does not look like it is coming from Baserow’s API server nor internal Caddy, but instead some other http server. Is there a chance that in your own Caddyfile that routes some requests to Baserow, that it could be incorrectly matching and miss routing some requests to Baserow?
@nigel I have found the problem. Unfortunately I have completely wasted your time with this issue.
I have been digging deeper into the requests made from my browser. The problem was that there was a conflicting DNS record on the subdomain the new baserow instance was running on.
Thank you very much for your help and sorry for the time waste.
No worries at all glad you got it all working. These are always useful data points in helping out future users and figuring out how to make our error handling/display/debugging tools work better in the future.
 ,
,