Please, is it somehow possible to filter only “not unique” text strings? Let’s say I have a people database of 2500+ records, where first column (data field) is a single text type with “Name Surname”. I would like to filter out only records where Name Surname are the same (identical), just to find duplicities. In a footer I have set the parameter to “Unique”, so I see that I have 7 duplicities. Now, I would like to find them as fast and simply as possible. Thanks.
Hello @marcus, we have discussed this request with the team, and we think it will be even more useful if we add the possibility to filter by unique and non-unique values. What do you think about this idea?
How would it work? You will just add the conditions “is unique” and “is non-unique” for all field types where it makes sense (at least text-type field, but maybe others too)? If yes, then sure it will be helpful, especially when seeking for duplicates.
Yep, we will introduce two new filters: one to only show values that are unique, where only one exists in the table, and the non-unique one to show values where there are at least two occurrences in the table.
Wonderful!!! This will make the duplicity search a lot easier.
That should be related to one (any) field. Or optionaly checkbox to match the non-unique value for the whole row (all fields in the row) - but this one (checkbox) is I believe not as much necessary/important.
Yes, this one could be a very special and extremely useful feature as soon as it is implemented. Do you agree, @olgatrykush ?
… still waiting and eager for it.
Olga, thanks for the info.
Just today I was browsing through our database table with almost 8000 rows (people’s names and all data associated with them), where we have 264 people with the same name. I was trying to figure out, how to filter and get visible only rows where the full name is non-unique (= it’s present in my table more times than just only once), but have no solution.
I am able to sort by surname (thanks to a special formula field that extracts the surname from full name - doesn’t work 100% but good enough), but going manually through 8000 rows is not a solution. Btw. I cannot simply delete non-unique (in terms of “same full name”) rows, because there can more same full names, but they are different persons - so I always need to visually check rest of data and consider if I will delete row(s) as a duplicity or not.
TL;DR - having the solution to filter duplicity (non-unique) data (at least from one field, of course being able to combine more data fields would be fantastic!) could be a very helpful feature.
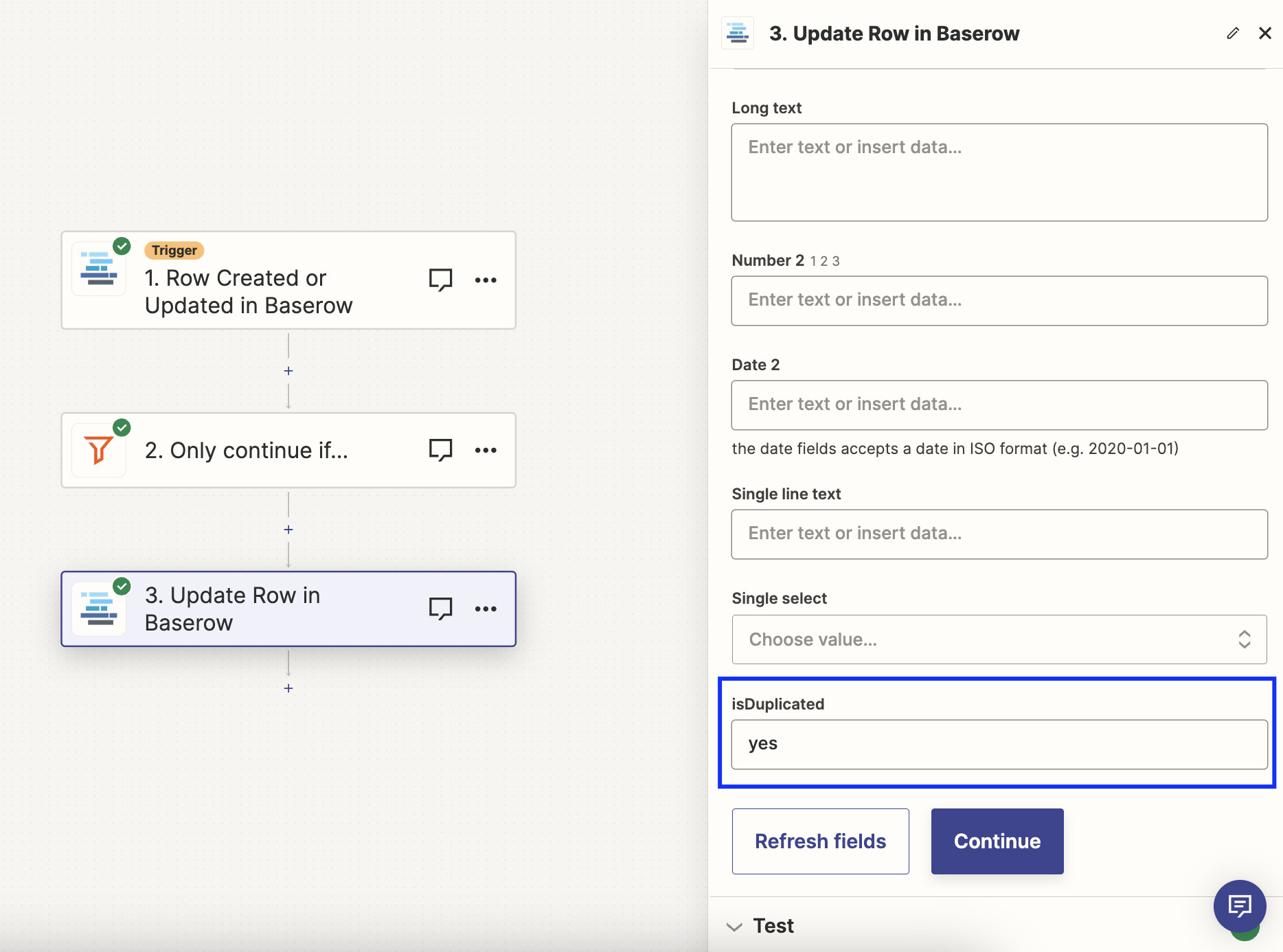
We understand that this is an important feature. While we currently don’t have it, you can use automation tools like Zapier to get a temporary solution. Here is an example of a simple workflow that should do what you need: it runs when a row is created or updated and checks if a record already exists. If it does, it updates a row by adding “Yes” to the ‘IsDuplicated?’ field.
Hi Olga,
thanks, I will check the Zapie/n8n/… solution and also that post from frederic.
Although my scenario i a bit specific, because:
all data in our database (tables) are sensitive, so we don’t want them to leave our local network (so not even to cloud services) - so I will need to find out whether one of them (which will do what we need) can be self-hosted.
full-automated duplicity removal process is not what I really need - I have to decide which rows are duplicated (so I’ll remove one or more of them, OR merge some data from them together to just one row) and which are unique, even that they contain the same data in that field which would be used as a reference of duplicities. Typically it’s the name of a person (so as I said).
That means: filtering is just that function I am seeking for, the next step will be always to consider manually/visually if it is a duplicity or not (and then delete OR keep it).
Sure, these are temporary solutions until we have filters in Baserow. Moreover, our content lead is currently working on a tutorial that will give detailed instructions for building this workflow to find duplicates.