Is there a straightforward way to move the content of a column to another?
I have a large dataset and need to move fields in a column to another column in the same table. Is there an easy way to do this, without copying 200 fields at one?
You can create a new column of the type formula. The formula will simply be a reference to the field you want to copy from: field('name of the field').
Next, you can change the type of formula column to the data type you prefer. I think this is the quickest way to move the data.
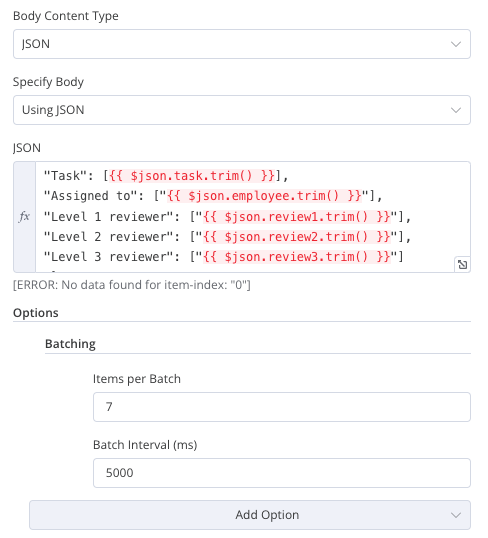
The cloud version of Baserow only supports 10 concurrent API requests. So, when using n8n you need to set the batch option on and set a certain number of requests (for example 7) for an amount of time (for example: 5 seconds).
I tried the first option i.e. using a formula. However, for some reason, ai prompt fields can’t be referenced in formulas. I tried changing the field type from ai prompt to single text, single select and rating, but that didn’t work too.
Also, n8n’s Baserow node doesn’t have the batching option, so I assume you’re using the http node in the example above. I’d like to use it but, but setting it up is not quite straightforward.
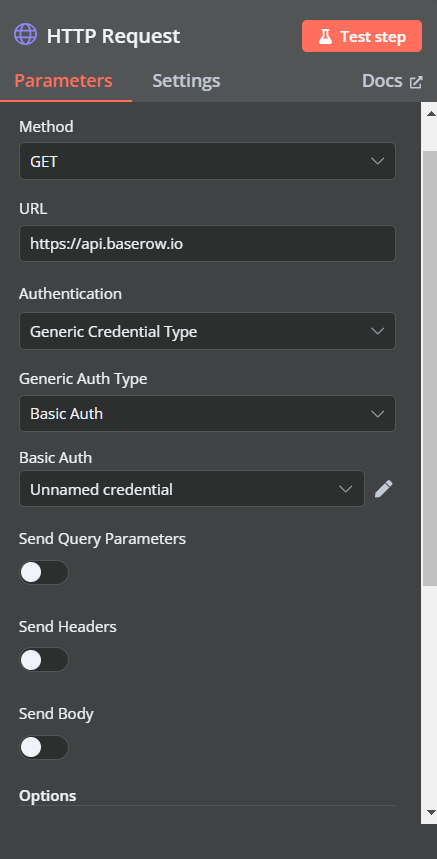
The URL in Baserow’s API docs is https://api.baserow.io but I get the error "
404 - “{"error": "URL_NOT_FOUND", "detail": "URL / not found."}”.
I think I’m missing out some extra queries in the URL but a quick google search or even the API doc doesn’t solve this.
Also, regarding authentication, I selected generic credential type, since Baserow is not in the predefined option. I then tried the Header Auth type with the name and database token and Basic auth, but neither worked.
Is there anything I’m doing wrong?
Also, is there anything I need to do in particular to get all the fields in the first 10 rows, i.e. include a query parameter, send header, send body, include response setting or anything else?
Correct, the AI field is a kind of special field because the content is generated by the external language model.
Also, n8n’s Baserow node doesn’t have the batching option, so I assume you’re using the http node in the example above.
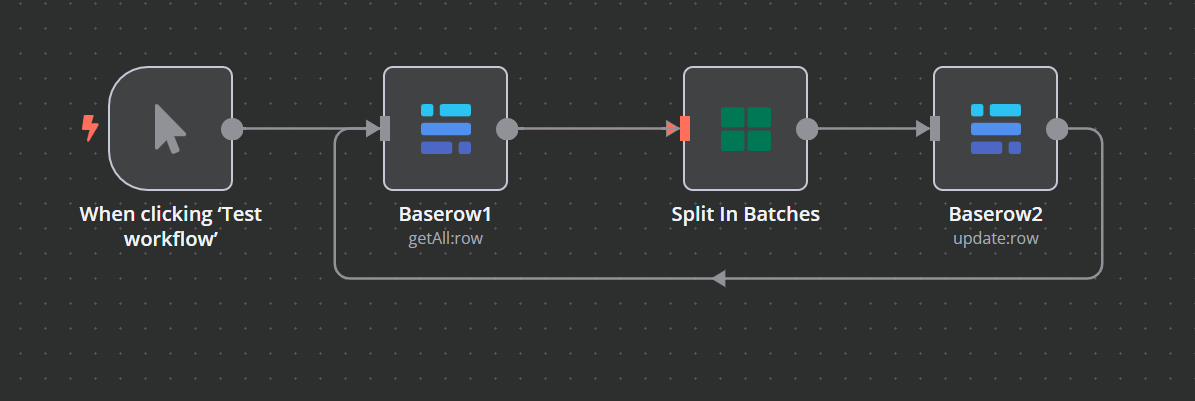
Indeed. This means that you need to set everything yourself which can be hard if you are not used to working with the API endpoints. So, I think it is easier to try solving the “Split in batches” node problem. Does this works for the first 10 records?
Yes, when I tried the split in batches node, it split the output from the Baserow node, but the issue comes from the Baserow1 node itself - it can’t output all the data without running out of memory. Since it can’t output it all, the split in batch node is redundant. I can’t filter using the Baserow node too. Besides, even if I filter, there’s no assurance it’ll output all 100k fields.
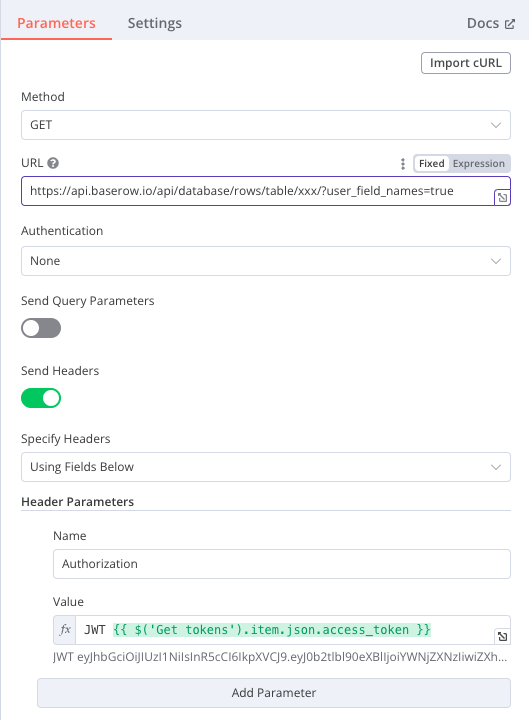
I’m pretty sure I can figure something out using the API endpoints. I just need to make the authentication work first. If you can tell me what I’m missing out, that’ll be great.
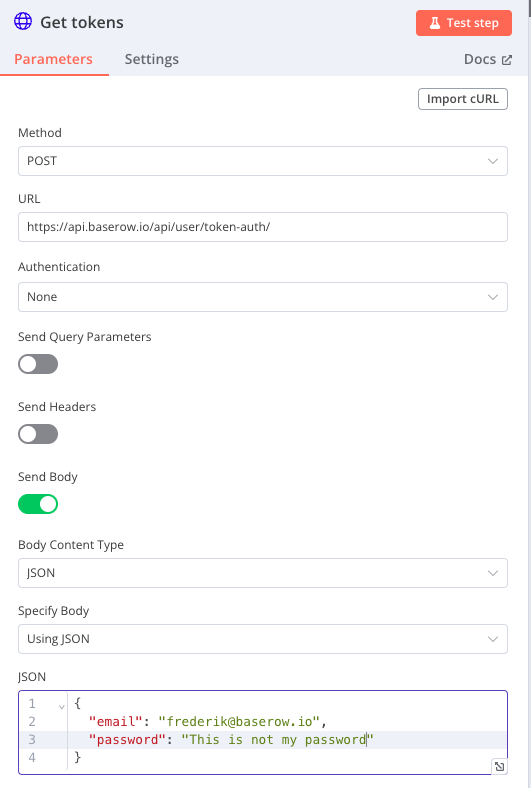
To get a token, you make a POST request to the following endpoint: https://api.baserow.io/api/user/token-auth/. In the body you create a JSON object providing your username and password