Are you using our SaaS platform (Baserow.io) or self-hosting Baserow?
SaaS
What are the exact steps to reproduce this issue?
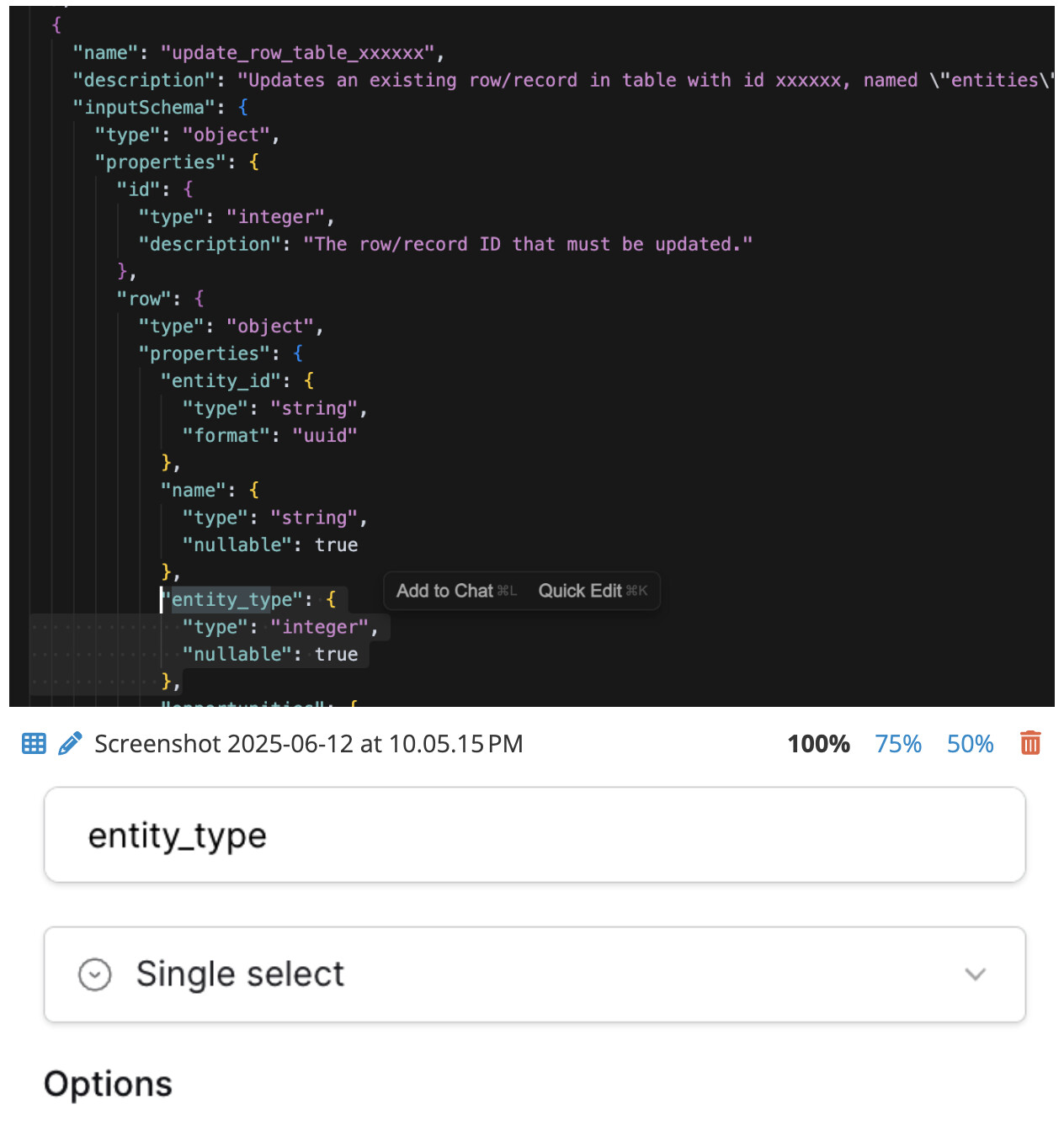
Use the MCP server, try to create or update a row that has a single select or multi select field, then when the MCP client provides an integer value for the single/multi select option the server rejects the create/update call, but when it provides the string value of that option, it works server side, but the schema validation of the input arguments of the tool call fail. For MCP clients that strictly validate the tool input arguments this leads to an impossibility of creating/updating rows with single/multi select fields.
Hey @rlamers, how does the tool call look like specifically for you, and which software are using to integrate with Baserow using the MCP?
When I was testing this with Claude, it was working as expected. However, I can see where this could go wrong because it accepts both an int and string as type. If an int is provided, then a lookup will be done on the select option ID, but if a string is provided, then on the name.
Maybe we can improve how this works from our side by including the option IDs in the property description of schema.
I quickly looked at the MR and I recall the MCP server actually not even accepting a correct integer ID for the option (I looked up the ID through using the frontend and finding option names having IDs in their ‘value’ property). Not sure if the MR addresses that, but would be good to test.
Yes, that will be addressed in this merge request. There was a problem in how the MCP tool forwards the request to the API. The data structure was wrong, causing integers to be converted to strings. This has been fixed.
Calude.ai and Claude Code experience the same thing now. Their report is:
The error is select_for_update cannot be used outside of a transaction. Here’s the technical summary:
select_for_update() is a Django ORM call that locks a row during a read-before-write operation. Django requires it to be wrapped in an atomic() transaction block. Somewhere in Baserow’s MCP server implementation, a write operation (create, update) is calling select_for_update() outside that block — most likely a race condition or a missing with transaction.atomic(): wrapper introduced in a recent Baserow release.
What works: read operations (list, search, schema, delete — delete doesn’t use select_for_update).
What’s broken: create and update — both write paths. Two connectors, same error, three days — this is a Baserow-side regression, not our configuration.
I tried to recreate the MCP connector, but encountered the same problem. Has this issue been resolved, or is there a workaround?
Confirming this on our self-hosted instance — with additional detail on the root cause and a data-integrity angle that may not be in the thread yet.
Environment
Baserow self-hosted, version 2.2.2
Backend served via ASGI (Server: uvicorn confirmed in response headers)
PostgreSQL backend
Accessed through the built-in MCP server endpoint (/mcp//sse) via the mcp-remote stdio<->SSE bridge
Symptom
Every MCP write tool call (create_rows) returns:
Error: select_for_update cannot be used outside of a transaction.
MCP read tools (list_databases, list_tables, get_table_schema, list_table_rows) work fine. The identical write via the REST API (POST /api/database/rows/table/{id}/) also works fine. So the fault is specific to the MCP server’s write path.
Data-integrity angle (the important part)
Despite returning an error, the row is actually created and committed. The caller sees a failure, but a row appears in the table. A client that retries on error therefore produces duplicates — in our case 4 retries created 4 duplicate rows plus the
original. This isn’t just a feature outage; it’s silent partial-write + duplication.
Root cause analysis select_for_update cannot be used outside of a transaction is Django’s TransactionManagementError, raised when QuerySet.select_for_update() runs with the DB connection in autocommit mode and no active transaction.atomic() block.
Baserow’s REST mutating endpoints execute inside a transaction (ATOMIC_REQUESTS / explicit atomic()), so the row-creation logic — which internally uses select_for_update to lock rows for order computation and link-field integrity — works correctly.
The built-in MCP server’s write tools dispatch into the same RowHandler code, but the MCP tool-handler path is not wrapped in transaction.atomic(). Under autocommit, the internal select_for_update raises immediately.
Because there is no surrounding transaction, the work completed before the failing select_for_update (the row INSERT, and link/m2m writes) is auto-committed and never rolled back → error returned to the client and an orphan row left behind.
Workaround
Use the REST API with a Database token for writes; the MCP endpoint remains usable for reads.