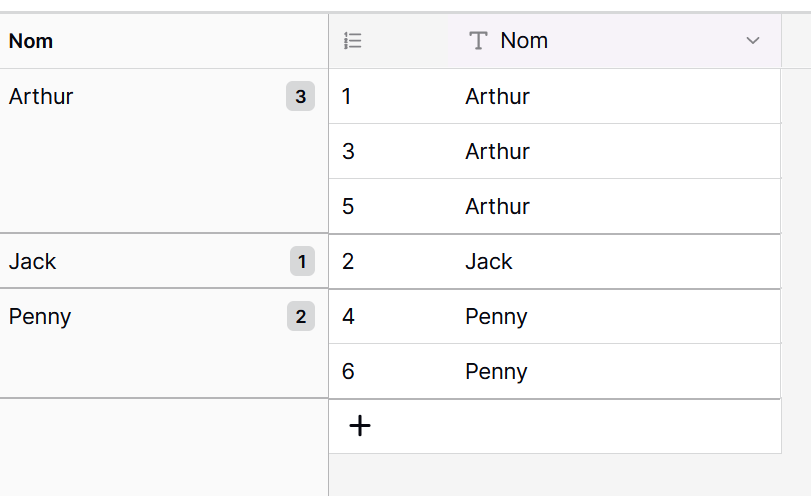
Hey! I think it would super useful to be able to order by “group by” occurrences. For instance here, I would be able to order by descending occurrences and have Arthur coming first, followed by Penny, followed by Jack:
Am I clear enough?
I think this could be game changing for duplicates management.
Cheers!
Hello @Anatole, we plan to make it possible to change orders of groups using drag and drop: Change order of group by (#2434) · Issues · Baserow / baserow · GitLab, is it what you are asking for?
1 Like
Hello @olgatrykush, thanks for the reply!
Not exactly, I would like to automatically order by “group by” occurrences (ascending or descending).
For instance, if I want to find quickly a duplicate inside a 1000 rows database, I would first group by, and then order by descending “group by” occurrences. Thus, the two identical rows would be at the top of the table view. Do you see what I mean?
Got you, thanks for the clarification. I’ll discuss the feature request with the team. 
We also have this issue regarding the detection of duplicates: Detect and delete duplicate rows (#611) · Issues · Baserow / baserow · GitLab. Soon, it will be possible to find duplicates and delete them or replace them with other text.
2 Likes
Hi @Anatole, we’ve talked about your idea and think it would be better to create a dedicated feature for identifying duplicates. As previously mentioned, this is already in our roadmap. 
Thanks for the reply! This brings me a question about the planned feature for identifying duplicates. Will it be able to find rows that are similar but not entirely identical (ie wich have some identical values but also some discrepancies)?
For instance, if I have one person who fills twice a form with the same email but with a different name, would this feature be able to find it still?
Hey @Anatole, I’ve asked the dev team and will keep you posted!
Hey @Anatole, we’re not 100% sure about how this feature will be implemented yet. The current idea is to add a side panel on the right side with a button to scan your table for duplicates. After scanning, a list of duplicates will appear, and you’ll be able to choose whether to delete or edit them. For instance, if there are two identical emails in your table, they will be flagged as duplicates. Is it what you’re looking for?
Or maybe you’re more interested in the field value constraints feature: Field value constraints (#647) · Issues · Baserow / baserow · GitLab?
Value constraints set limits on the values that can be added to the field. For instance, you can restrict the field from having duplicate values.