We are running a self-hosted version of Baserow. I chose Baserow due to the simplicity, but i’m running into performance issues with our API’s. The APIs are so slow, even 300,000 ms Timeouts are kicking in on a filter API.
Hi @dalekirkwood, thank you for sharing all the information. I don’t think I’ve ever seen someone running Baserow with so many rows in in their tables.
Can you give me insight how many API requests you’re making to the server? And also what kind of requests you’re making? Do they list rows using a search query, filters, sorts, etc. Are many rows being created, updated or deleted? Anything could requests.
Some additional questions:
Which version of Baserow do you currently run?
How many fields do you have in each table?
Have you thought about splitting Baserow up into multiple services? This will help you to identify where the bottleneck might me.
Multiple application servers.
Separate PostgreSQL server.
Separate Redis server.
If you can reduce the number of rows, then do that, it will help.
There are many things that can cause performance problems. Some things that come top of mind:
Your table is huge, and Baserow tries to add it to add every row to the search index. This process is CPU intensive, can time out, and constantly restart.
If you’re making many update requests to the same row, basically a new request before the other one has completed, could put the gunicorn workers in a deadlock.
The bottleneck might be in the PostgreSQL database server.
Some other notes:
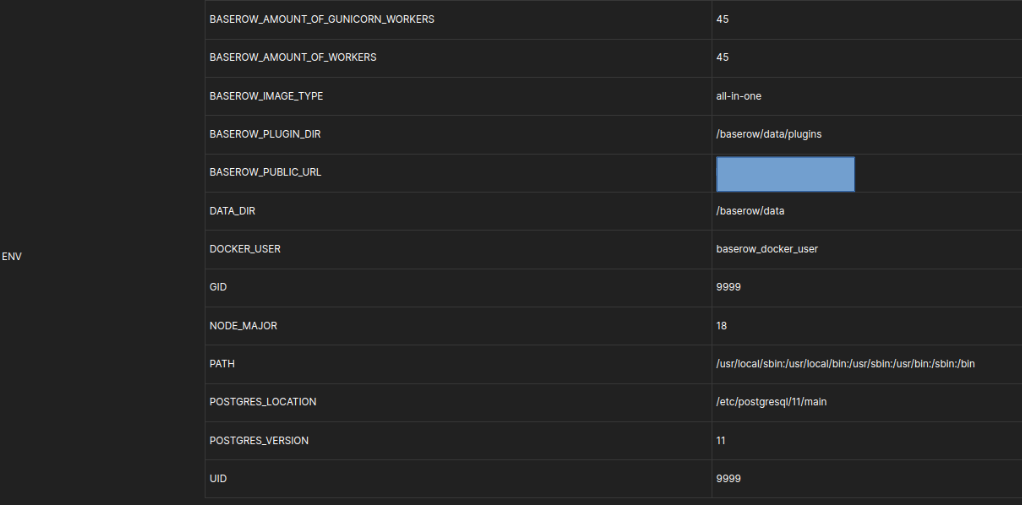
If you’re using 20GB memory, then there is room to scale the gunicorn workers up even more to handle more concurrent API requests, although I’m not really sure how well 45+ gunicorn workers work in combination with an 8 core CPU. Every gunicorn worker should consume around 150MB of memory.
Anyway, these are all just some thoughts. It would be great to get more insights in what you’re doing if I want to help.