Hi.
Since i updated my instance to the latest version, a few days ago, my instance starts giving 500 - Internal Server Error within a few hours of restarting the server, and another few hours after that, the server itself becomes completely inaccessible. Only option left then is to hard reset it as well as restart the docker container.
This has started happening only after the latest update
My setup is docker-compose based
No other app is hosted on this machine
The Droplet graphs shows RAM usage reaching 92% (of 2GB) when the server becomes completely inaccessible. It starts at around 55% after server restart.
What could be the issue?
How to go about resolving it?
Perhaps our problems are connected.
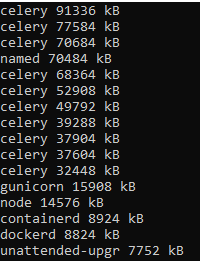
In my case, while RAM is at a stable level, SWAP memory is steadily increasing.
After checking what is eating the SWAP, it turns out that it is celery from the baserow backend.
Thanks for the more detailed information. We did increase usage of celery and async tasks in 1.11 so this will be a great help looking for this memory leak.
With regards to the unhealthy celery beat worker, this container doesn’t have a health check because the celery beat service itself doesn’t have a health check. The default docker-compose file provides a default no-operation health check for it which should always just show healthy, so i’m surprised it shows unhealthy for you @rafuru . Could let me know what the healthcheck section is for your celery-beat-worker service in your docker-compose? Either way this fake healthcheck is unrelated to the memory leak described above.
And just to check @shrey and @rafuru if you have incorrectly set the BASEROW_BACKEND_DEBUG environment variable to the value of on? If so this will switch celery into debug mode, which will cause a memory leak as warned in the logs by celery on startup?
Additionally could you provide a log dump for the 2 hour period or so between restarts and your docker-compose configuration?
version: "3.4"
########################################################################################
#
# READ ME FIRST!
#
# Use the much simpler `docker-compose.all-in-one.yml` instead of this file
# unless you are an advanced user!
#
# This compose file runs every service separately using a Caddy reverse proxy to route
# requests to the backend or web-frontend, handle websockets and to serve uploaded files
# . Even if you have your own http proxy we recommend to simply forward requests to it
# as it is already properly configured for Baserow.
#
# If you wish to continue with this more advanced compose file, it is recommended that
# you set environment variables using the .env.example file by:
# 1. `cp .env.example .env`
# 2. Edit .env and fill in the first 3 variables.
# 3. Set further environment variables as you wish.
#
# More documentation can be found in:
# https://baserow.io/docs/installation%2Finstall-with-docker-compose
#
########################################################################################
# See https://baserow.io/docs/installation%2Fconfiguration for more details on these
# backend environment variables, their defaults if left blank etc.
x-backend-variables: &backend-variables
# Most users should only need to set these first four variables.
SECRET_KEY: ${SECRET_KEY:?}
DATABASE_PASSWORD: ${DATABASE_PASSWORD:?}
REDIS_PASSWORD: ${REDIS_PASSWORD:?}
# If you manually change this line make sure you also change the duplicate line in
# the web-frontend service.
BASEROW_PUBLIC_URL: ${BASEROW_PUBLIC_URL-http://localhost}
# Set these if you want to use an external postgres instead of the db service below.
DATABASE_USER: ${DATABASE_USER:-baserow}
DATABASE_NAME: ${DATABASE_NAME:-baserow}
DATABASE_HOST:
DATABASE_PORT:
DATABASE_URL:
# Set these if you want to use an external redis instead of the redis service below.
REDIS_HOST:
REDIS_PORT:
REDIS_PROTOCOL:
REDIS_URL:
REDIS_USER:
# Set these to enable Baserow to send emails.
EMAIL_SMTP:
EMAIL_SMTP_HOST:
EMAIL_SMTP_PORT:
EMAIL_SMTP_USE_TLS:
EMAIL_SMTP_USER:
EMAIL_SMTP_PASSWORD:
FROM_EMAIL:
# Set these to use AWS S3 bucket to store user files.
AWS_ACCESS_KEY_ID:
AWS_SECRET_ACCESS_KEY:
AWS_STORAGE_BUCKET_NAME:
AWS_S3_REGION_NAME:
AWS_S3_ENDPOINT_URL:
AWS_S3_CUSTOM_DOMAIN:
# Misc settings see https://baserow.io/docs/installation%2Fconfiguration for info
BASEROW_AMOUNT_OF_WORKERS:
BASEROW_ROW_PAGE_SIZE_LIMIT:
BATCH_ROWS_SIZE_LIMIT:
INITIAL_TABLE_DATA_LIMIT:
BASEROW_FILE_UPLOAD_SIZE_LIMIT_MB:
BASEROW_EXTRA_ALLOWED_HOSTS:
ADDITIONAL_APPS:
BASEROW_PLUGIN_GIT_REPOS:
BASEROW_PLUGIN_URLS:
BASEROW_ENABLE_SECURE_PROXY_SSL_HEADER:
MIGRATE_ON_STARTUP: ${MIGRATE_ON_STARTUP:-true}
SYNC_TEMPLATES_ON_STARTUP: ${SYNC_TEMPLATES_ON_STARTUP:-true}
DONT_UPDATE_FORMULAS_AFTER_MIGRATION:
BASEROW_TRIGGER_SYNC_TEMPLATES_AFTER_MIGRATION:
BASEROW_SYNC_TEMPLATES_TIME_LIMIT:
BASEROW_BACKEND_DEBUG:
BASEROW_BACKEND_LOG_LEVEL:
FEATURE_FLAGS:
PRIVATE_BACKEND_URL: http://backend:8000
PUBLIC_BACKEND_URL:
PUBLIC_WEB_FRONTEND_URL:
MEDIA_URL:
MEDIA_ROOT:
BASEROW_AIRTABLE_IMPORT_SOFT_TIME_LIMIT:
HOURS_UNTIL_TRASH_PERMANENTLY_DELETED:
OLD_ACTION_CLEANUP_INTERVAL_MINUTES:
MINUTES_UNTIL_ACTION_CLEANED_UP:
BASEROW_GROUP_STORAGE_USAGE_ENABLED:
BASEROW_GROUP_STORAGE_USAGE_QUEUE:
BASEROW_COUNT_ROWS_ENABLED:
DISABLE_ANONYMOUS_PUBLIC_VIEW_WS_CONNECTIONS:
BASEROW_WAIT_INSTEAD_OF_409_CONFLICT_ERROR:
BASEROW_FULL_HEALTHCHECKS:
BASEROW_DISABLE_MODEL_CACHE:
BASEROW_PLUGIN_DIR:
BASEROW_JOB_EXPIRATION_TIME_LIMIT:
BASEROW_JOB_CLEANUP_INTERVAL_MINUTES:
BASEROW_MAX_ROW_REPORT_ERROR_COUNT:
BASEROW_JOB_SOFT_TIME_LIMIT:
BASEROW_INITIAL_CREATE_SYNC_TABLE_DATA_LIMIT:
BASEROW_MAX_SNAPSHOTS_PER_GROUP:
BASEROW_SNAPSHOT_EXPIRATION_TIME_DAYS:
services:
# A caddy reverse proxy sitting in-front of all the services. Responsible for routing
# requests to either the backend or web-frontend and also serving user uploaded files
# from the media volume.
caddy:
image: caddy:2
restart: unless-stopped
environment:
# Controls what port the Caddy server binds to inside its container.
BASEROW_CADDY_ADDRESSES: ${BASEROW_CADDY_ADDRESSES:-:80}
PRIVATE_WEB_FRONTEND_URL: ${PRIVATE_WEB_FRONTEND_URL:-http://web-frontend:3000}
PRIVATE_BACKEND_URL: ${PRIVATE_BACKEND_URL:-http://backend:8000}
ports:
- "${HOST_PUBLISH_IP:-0.0.0.0}:${WEB_FRONTEND_PORT:-80}:80"
- "${HOST_PUBLISH_IP:-0.0.0.0}:${WEB_FRONTEND_SSL_PORT:-443}:443"
volumes:
- $PWD/Caddyfile:/etc/caddy/Caddyfile
- media:/baserow/media
- caddy_config:/config
- caddy_data:/data
healthcheck:
test: [ "CMD", "wget", "--spider", "http://localhost/caddy-health-check" ]
interval: 10s
timeout: 5s
retries: 5
networks:
local:
backend:
image: baserow/backend:1.11.0
restart: unless-stopped
environment:
<<: *backend-variables
depends_on:
- db
- redis
volumes:
- media:/baserow/media
networks:
local:
web-frontend:
image: baserow/web-frontend:1.11.0
restart: unless-stopped
environment:
BASEROW_PUBLIC_URL: ${BASEROW_PUBLIC_URL-http://localhost}
PRIVATE_BACKEND_URL: ${PRIVATE_BACKEND_URL:-http://backend:8000}
PUBLIC_BACKEND_URL:
PUBLIC_WEB_FRONTEND_URL:
BASEROW_DISABLE_PUBLIC_URL_CHECK:
INITIAL_TABLE_DATA_LIMIT:
DOWNLOAD_FILE_VIA_XHR:
BASEROW_DISABLE_GOOGLE_DOCS_FILE_PREVIEW:
HOURS_UNTIL_TRASH_PERMANENTLY_DELETED:
DISABLE_ANONYMOUS_PUBLIC_VIEW_WS_CONNECTIONS:
FEATURE_FLAGS:
ADDITIONAL_MODULES:
BASEROW_MAX_IMPORT_FILE_SIZE_MB:
BASEROW_MAX_SNAPSHOTS_PER_GROUP:
depends_on:
- backend
networks:
local:
celery:
image: baserow/backend:1.11.0
restart: unless-stopped
environment:
<<: *backend-variables
command: celery-worker
# The backend image's baked in healthcheck defaults to the django healthcheck
# override it to the celery one here.
healthcheck:
test: [ "CMD-SHELL", "/baserow/backend/docker/docker-entrypoint.sh celery-worker-healthcheck" ]
depends_on:
- backend
volumes:
- media:/baserow/media
networks:
local:
celery-export-worker:
image: baserow/backend:1.11.0
restart: unless-stopped
command: celery-exportworker
environment:
<<: *backend-variables
# The backend image's baked in healthcheck defaults to the django healthcheck
# override it to the celery one here.
healthcheck:
test: [ "CMD-SHELL", "/baserow/backend/docker/docker-entrypoint.sh celery-exportworker-healthcheck" ]
depends_on:
- backend
volumes:
- media:/baserow/media
networks:
local:
celery-beat-worker:
image: baserow/backend:1.11.0
restart: unless-stopped
command: celery-beat
environment:
<<: *backend-variables
# See https://github.com/sibson/redbeat/issues/129#issuecomment-1057478237
stop_signal: SIGQUIT
# We don't yet have a healthcheck for the beat worker, just assume it is healthy.
healthcheck:
test: [ "CMD-SHELL", "exit 0" ]
depends_on:
- backend
volumes:
- media:/baserow/media
networks:
local:
db:
image: postgres:11
restart: unless-stopped
environment:
- POSTGRES_USER=${DATABASE_USER:-baserow}
- POSTGRES_PASSWORD=${DATABASE_PASSWORD:?}
- POSTGRES_DB=${DATABASE_NAME:-baserow}
healthcheck:
test: [ "CMD-SHELL", "su postgres -c \"pg_isready -U ${DATABASE_USER:-baserow}\"" ]
interval: 10s
timeout: 5s
retries: 5
networks:
local:
volumes:
- pgdata:/var/lib/postgresql/data
redis:
image: redis:6
command: redis-server --requirepass ${REDIS_PASSWORD:?}
healthcheck:
test: [ "CMD", "redis-cli", "ping" ]
networks:
local:
# By default, the media volume will be owned by root on startup. Ensure it is owned by
# the same user that django is running as, so it can write user files.
volume-permissions-fixer:
image: bash:4.4
command: chown 9999:9999 -R /baserow/media
volumes:
- media:/baserow/media
networks:
local:
volumes:
pgdata:
media:
caddy_data:
caddy_config:
networks:
local:
driver: bridge
docker-compose logs in the folder where the docker-compose.yml is should do the trick. You might want to PM it me directly instead of posting it publicly.
One immediate thing you can try is explicitly setting the BASEROW_AMOUNT_OF_WORKERS=2 environment variable in your .env file.
This env variable controls the number of concurrent processes our celery queues launch. If not set then celery defaults to a value equal to the number of cpu cores available (Command Line Interface — Celery 5.2.7 documentation).
Instead by setting this env var you can force celery to only launch X processes, which should dramatically decrease your initial memory usage. If you don’t have lots of concurrent users doing slow operations (exporting, duplicating, snapshotting etc) then setting this to a value of 2 should be more than enough.
Now this might not fix the slow memory leak that you are seeing, but hopefully at the minimum it should give you much more time between restarts.
This issue is still persistent, consistently, rendering the instance rather unstable and thus, practically useless.
Also, i’m unable to decipher anything using the logs because i can run docker-compose logs only after restarting the server and then the containers, and at that time, the logs contain only the restart info.
Are the logs being dumped anywhere else as well, so that we can retrieve more historical data?
Either way, kindly guide as to how to resolve this issue.
PS: i did upgrade to the latest version, a few days ago.
docker-compose logs should show historical logs between container restarts. Are you potentially not scrolling up? One command you can try is docker-compose logs > logs.txt to get all the contents of the logs.
I’ve tried to replicate this issue locally and unfortunately I can’t. My next suggestion if you’d be willing to do so (and not problem if not) is providing me privately a copy of your entire Baserow data volume so I can see if there is something specific going on in your instance triggering this.
Additionally information of what exactly the specs of your droplet are might help so I can attempt to replicate exactly. Perhaps you could try remaking the droplet with more resources (CPU and RAM) and seeing if this helps?
Hi @shrey , at this we’d need direct access of some form to your Baserow server and/or database to fully debug this issue. Your logs etc have confirmed that the backend and celery workers do have some sort of memory leak, but the tooling/steps to actually diagnose what is going and fix this on needs a developer ideally. We’ve not been able to replicate this issue ourselves and otherwise we’ve run out of debugging steps to help.