Hi @Allllan okay, so I think your use-case will be straight forward once we have this PR released. Until then, we’re lacking some formula functions (like is_empty and length) to be able to neatly evaluate the previous node’s output.
In the meantime, I was able to get your use-case working doing this:
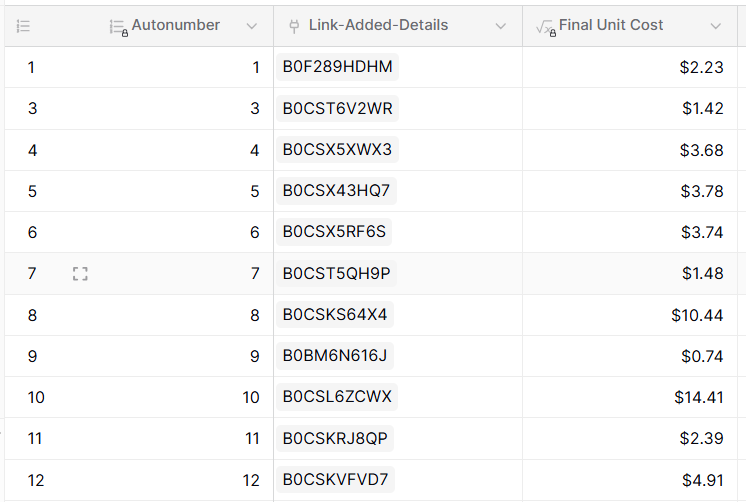
In my example, my first table is named “Fruits” and the second table is named “Fruit orders”. The “missing” row in my second table has the name “Unknown”.
In the screen recording, you’ll notice that the “Unknown” row is skipped, while the rest of the rows are processed.
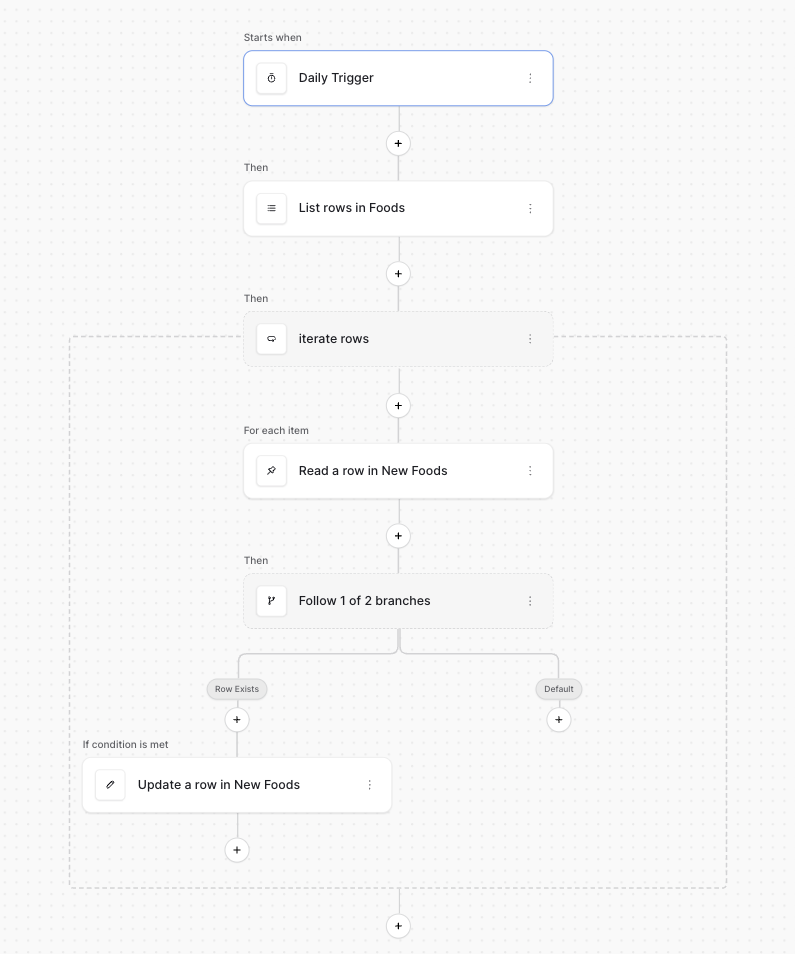
You’re right about me selecting the wrong table in my previous example, which I’ve fixed in the latest screen recording.
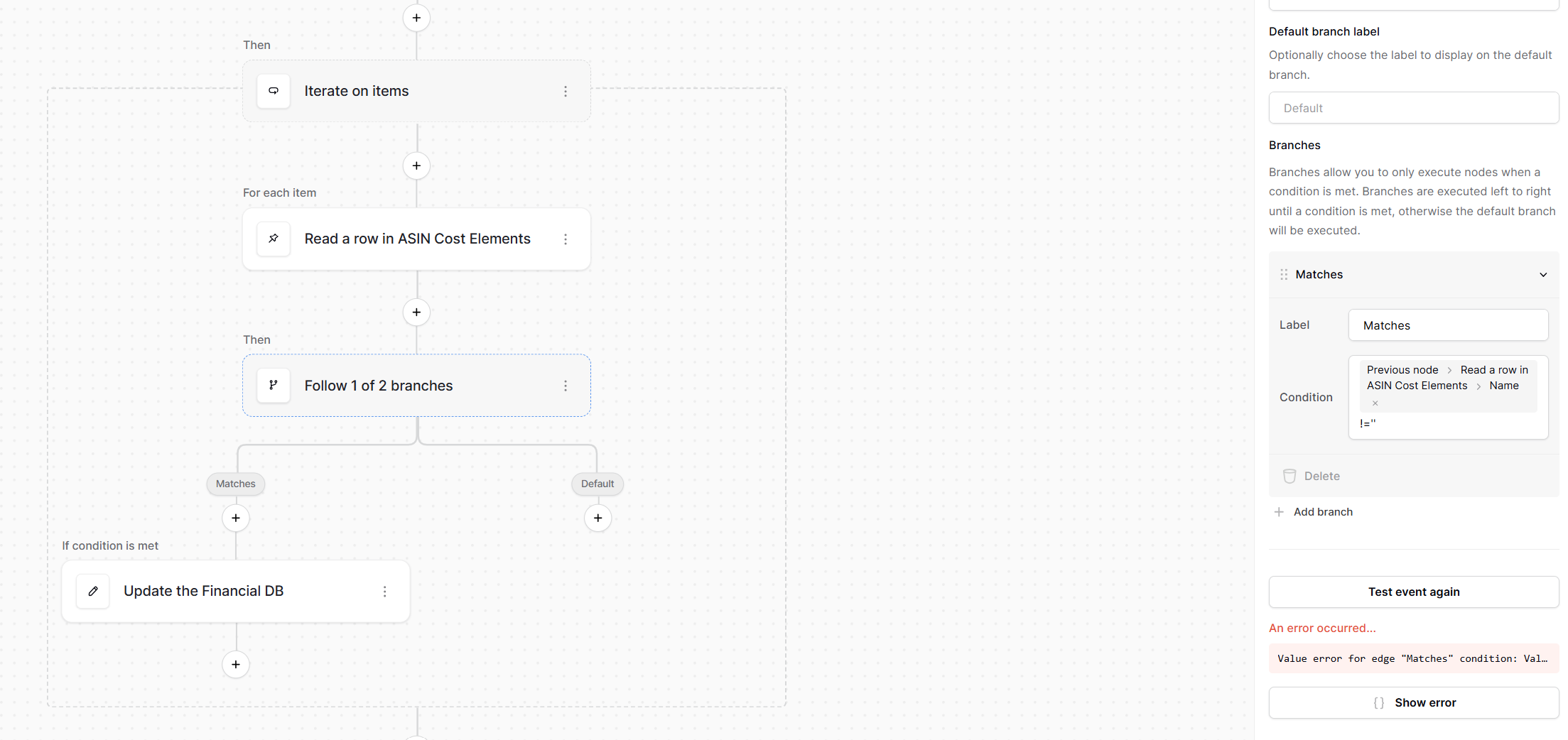
The biggest difference is the usage of the upper() formula in the Router node (i.e. “Follow 1 of 2 branches”). Here is why need to do this.
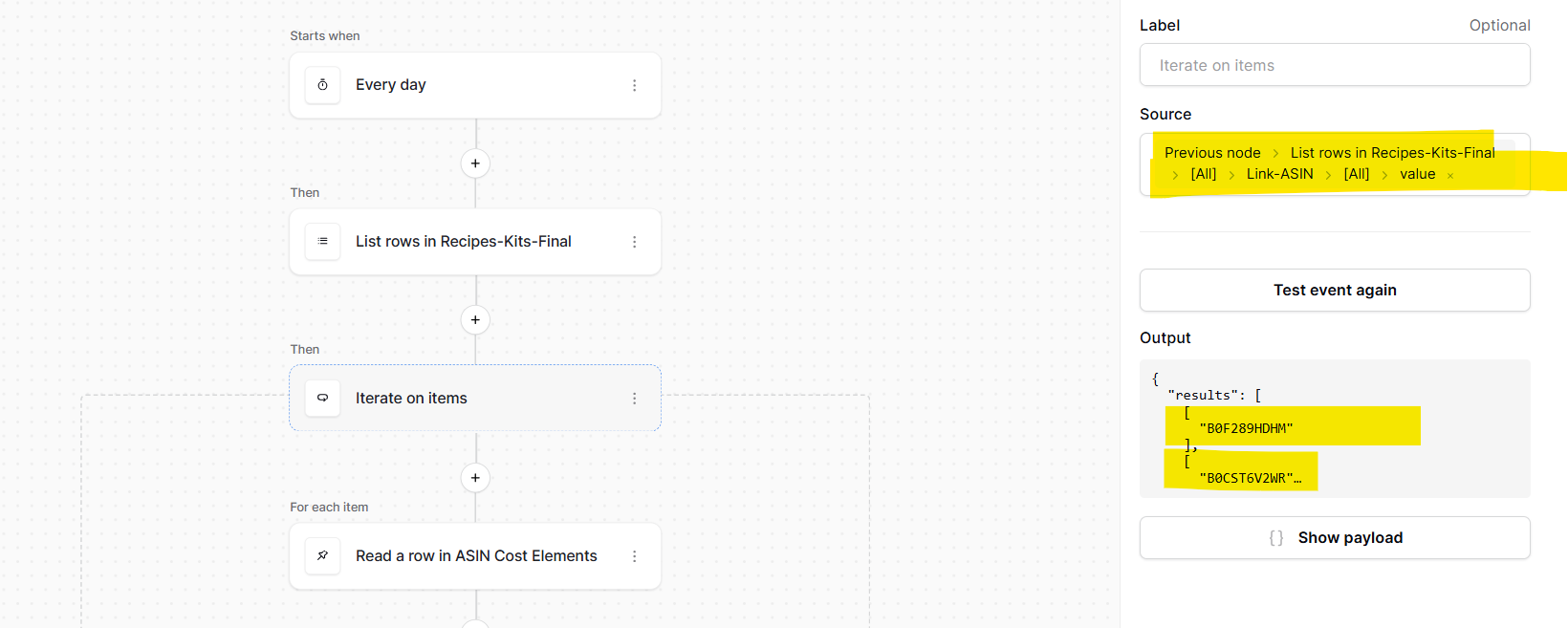
The “List rows in Fruit Orders” node will either return a list of data if it finds a row, otherwise it will return just [] (an empty array).
The “Follow 1 of 2 branches” node needs to know whether the above output is [] or not. The PR I mentioned earlier introduces the is_empty() and length() formula functions, which are able to directly evaluate whether the output is empty or not. However, since we don’t yet have these functions, we need another way to tell if the previous node is empty.
We therefore use the existing upper() formula function, which takes any input, converts it to a string, then upper cases it. Using this, we can convert [] to ”[]”; this allows us to compare this converted value against a literal string of ”[]”. Thus, when the previous output is not [] (because we matched on a row containing “Unknown”, i.e. a row that doesn’t exist in the first table), the branch node is selected.
I hope this makes sense. Sorry about the weird work-around, but once we have that PR merged and released, you should be able to simplify your automation workflow