Hey guys.
1. Disclaimer
1.1 I would like to contribute to this specific topic: Import information from bookmarks for Baserow. Initially, I thought I’d respond here instead of the topic, since I’d rather do an initial demo.
1.2. Add pip install to ‘requests’', ‘json’ and [chrome_bookmarks](https://pypi.org/project/chrome-bookmarks/)"
1.3 Maybe this can be easily solved with two libraries written in python: requests, json, chrome-bookmarks. In theory you can choose any bookmarks library in any programming language, as long as there is a library that communicates with the browser: google chrome, firefox, vivaldi etc.
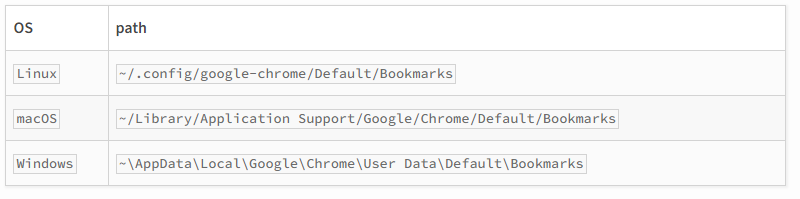
1.4 The files where the user saves their favorite websites by default are inside this file system. If you’ve exported anywhere else, it won’t work.
1.5 It would be advisable to set a link limit if you are using Baserow’s free plan
2. Basic Algorithm
2.1. Select the library that communicates with baserow, there are several in nodejs, python or php. Here in my example, I selected the library: requests in python.
2.2. Select a bookmarks library in some programming language that you know. Here I selected the library: chrome-bookmarks in python.
2.3. List the data and import it into an array. In computer science, an array is a data structure consisting of a collection of elements ( values or variables ), of same memory size, each identified by at least one array index or key.
2.4. View the listed data within an array
3. Idea or demo
In this basic algorithm, we use the requests library with the chrome-bookmarks library to import bookmarks of browser in Baserow. The purpose of this code is for demonstration only.
import requests
import json
import chrome_bookmarks
def apiHeader(token):
return {"Authorization": "Token " + token, "Content-Type": "application/json"}
def apiGet(id):
return "https://api.baserow.io/api/database/rows/table/"+id+"/?user_field_names=true"
def getBase(id, token):
return requests.get(apiGet(id), headers=apiHeader(token))
def postBase(id, token, string):
return requests.post(apiGet(id), headers=apiHeader(token), json={"urlName":string})
def listURLS():
return chrome_bookmarks.urls
def listToString(array):
return ' '.join([str(urlName) for urlName in array])
def viewPost(idTable, token):
return postBase(idTable, token, listToString(listURLS()))
viewGet('id_table', 'add_token', 'add_property')
viewPost('id_table', 'add_token')
3. Final considerations
3.1 What do you all think of this idea?
3.2 This code is in the public domain, use or modify it however you want.
3.3 The codebase of this code is the same one I developed to generate graphs in Baserow.
3.4 This code is something basic for demonstration purposes.
3.5 I hope to contribute in some way to the Baserow community.
3.6 Maximum of 3.000 rows per group/workspace in free plan(Baserow)
3.7 Maximum of 2GB of storage in free plan(Baserow)
3.8 Maximum of 1.000 monthly API requests in free plan(Baserow)
3.9 Support via the community, tutorials, FAQ, user docs in free plan(Baserow)
